文字コードの指定
プログラムの中に文字列が含まれていた場合には、Pythonはデフォルトの文字コードであるASCIIを使って文字を認識しようとします。この時、日本語などのマルチバイト文字が含まれていた場合にも文字コードのASCIIで認識しようとするため不適切な文字としてエラーとなります。
print "こんにちは"
上記を実際に実行してみると次のようにエラーとなります。
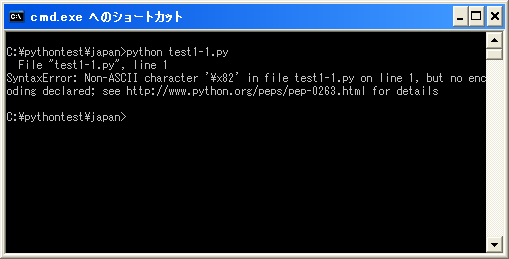
日本語などをプログラム内で使用する場合には、プログラムの文字コードの指定を行い、そしてその文字コードを使ってファイルを保存する必要があります。
Pythonのプログラムで使用する文字コードを指定するには次のように記述します。
# coding: エンコーディング名 # coding=エンコーディング名
上記の文字コードの指定はプログラムの1行目又は2行目に記述された場合にだけ有効です。Pythonにおいては「#」が現れた場合行末まではコメントとして扱われるため、1行目又は2行目ではない位置に記述された場合は単なるコメントとなります。
指定可能な文字コードは色々とありますが、代表的なものとしては次のようなものがあります。
# coding: Shift_JIS # coding: cp932 # coding: EUC-JP # coding: UTF-8
※大文字小文字は区別されませんので「utf-8」などと記述することも出来ます。
日本語を利用する場合は「Shift_JIS(又はcp932)」「EUC-JP」「UTF-8」などを設定します。どの文字コードを使わなければいけないというのはありませんが、Pythonにおいてはユニコード文字列を使用する時にUTF-8にしておくと便利なので今後のサンプルでは全て「UTF-8」で統一します。
結果として文字コードを指定したプログラムは次のような形式となります。
# coding: UTF-8 print "こんにちは"
またプログラムを保存する時の文字コードも、プログラムで指定した文字コードを使って保存して下さい。今回のようにプログラムの文字コードを「UTF-8」とした場合は、ファイルを保存する際の文字コードも「UTF-8」とします。
※UTF-8で保存する場合、BOM付き(UTF-8)とBOM無し(UTF-8N)のどちらで行うかですが、Pythonの場合はどちらがいいのかはっきりと分かりませんでした。ただBOM無しのUTF-8Nで保存しておいた方がよさそうではあります。Windowsのメモ帳はBOM付きしか選択できませんので他のエディタをお勧めします。
またマルチバイト文字を扱う場合、文字列は通常の文字列ではなくユニコード文字列を使います。詳しくは別のページで確認しますので、ここではあまり気にしないで下さい。ユニコード文字列では文字列の前に「u」が付きます。
#coding: UTF-8 print u"こんにちは"
上記を「test1-2.py」として保存します。保存する時の文字コードはUTF-8です。そして次のように実行して下さい。
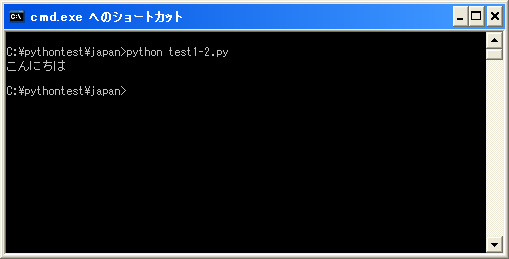
日本語も無事出力されました。
( Written by Tatsuo Ikura )
