インデックスを指定して要素を取得
文字列もシーケンス型の一つです。シーケンス型は複数の要素が順序を持って並べられたものであり、文字列で言えば、文字列を構成する1つ1つの文字が要素であり、要素が順番に並べられたものが文字列となります。
文字列を構成する個々の要素は個別に取得することが可能です。要素には先頭から順に番号が割り当てられています。この番号をインデックスと呼んでおり「0」「1」「2」...と0から順に番号が割り当てられています。この番号を使うことで要素を指定することが出来ます。(なおインデックスには負の値を指定することも可能です。負の値の場合は「-1」なら一番最後の要素、「-2」なら最後から二番目の要素となります)。
文字列の中でインデックスを指定して要素を取得するには次の書式を使います。
文字列オブジェクト[インデックス]
引数に指定したインデックスを持つ要素を取り出します。インデックスは0から始まることに注意して下さい。
具体的には次のように記述します。
str = "Hello" print str[0] # H print str[1] # e print str[2] # l print str[3] # l print str[4] # o
文字列は先頭の文字がインデックス0の要素、次の文字がインデックス1の要素となります。オブジェクト[インデックス]の形式で要素を取得すると、インデックスに対応した要素に含まれる文字を参照することが可能です。今回の場合は、文字列の中の文字を順に取得して出力しています。
またUnicode文字列も同じようにインデックスを指定して要素を取得できます。Unicode文字列では個々の要素は文字単位ですので、要素も文字単位となります。
str = u"表計算" print str[0] # 表 print str[1] # 計 print str[2] # 算
Unicode文字列ですので日本語などの全角文字であっても文字単位で取得することが出来ます。
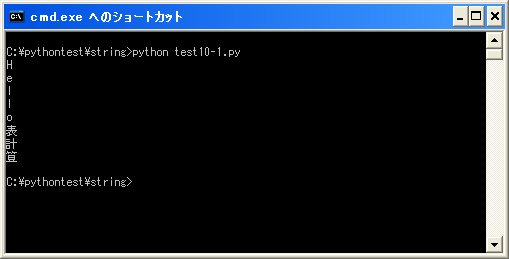
では実際に試してみます。
#coding: UTF-8 str = "Hello" print str[0] print str[1] print str[2] print str[3] print str[4] jpstr = u"表計算" print jpstr[0] print jpstr[1] print jpstr[2]
上記を「test10-1.py」として保存します。保存する時の文字コードはUTF-8です。そして次のように実行して下さい。
( Written by Tatsuo Ikura )
