スライスを使った部分文字列の取得
文字列やリストなどのシーケンス型のオブジェクトではスライスという機能を使用できます。これはオブジェクトの中の指定した範囲の要素を持つ新しいオブジェクトを作成して返してくれるものです。
スライスではどこからどこまでの要素を抽出するのかを指定する必要がります。例として「ABCDE」と言う文字列を使ってスライスの説明を行います。
0 1 2 3 4 5 | A | B | C | D | E |
文字列が「ABCDE」だった場合、インデックス0は最初の文字「A」の前、インデックス1は最初の文字「A」と次の文字「B」の間となります。そして抽出する文字の先頭の文字の前のインデックスから最後の文字の次のインデックスで指定します。例えば「BC」を取得する場合には、「B」の前のインデックス1から「C」の次のインデックス3を指定します。指定方法は次の通りです。
文字列オブジェクト[開始インデックス:終了インデックス]
開始インデックスと終了インデックスをコロン(:)でつなげて指定します。具体的には次のように記述します。
str = "ABCDE" slice = str[1:3] # "BC"
インデックスの指定方法には注意して下さい。
またインデックスにはマイナスの値も指定できます。インデックスと位置の関係は次の通りです。
-3 -2 -1
| A | B | C | D | E |
マイナスの値を使用する場合は、最後の文字の次のインデックスを指定できませんので、最後の文字は抽出できません。具体的には次のように記述します。
str = "ABCDE" slice = str[1:-1] # "BCD"
終了インデックスを省略すると最後の文字の次のインデックスが指定されたことになります。結果的に開始インデックスから最後の文字までが抽出されます。
文字列オブジェクト[開始インデックス:]
具体的には次のように記述します。
str = "ABCDE" slice = str[1:] # "BCDE"
開始インデックスを省略すると最初の文字の前のインデックスが指定されたことになります。結果的に先頭の文字から終了インデックスの前の文字までが抽出されます。
文字列オブジェクト[:終了インデックス]
具体的には次のように記述します。
str = "ABCDE" slice = str[:2] # "AB"
開始インデックスと終了インデックスを省略すると先頭の文字から最後の文字までが抽出されます。
文字列オブジェクト[:]
具体的には次のように記述します。
str = "ABCDE" slice = str[:] # "ABCDE"
このようにスライスを使うことで、対象のオブジェクトの中から一部分を抽出した新しいオブジェクトを作成することが可能となります。
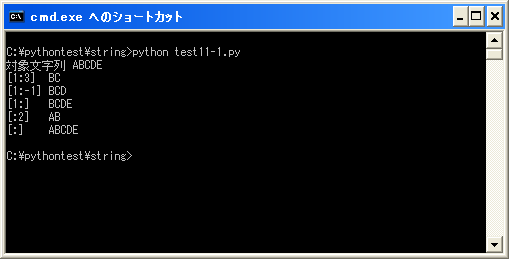
では実際に試してみます。
#coding: UTF-8 str = "ABCDE" print u"対象文字列 " + str print "[1:3] " + str[1:3] print "[1:-1] " + str[1:-1] print "[1:] " + str[1:] print "[:2] " + str[:2] print "[:] " + str[:]
上記を「test11-1.py」として保存します。保存する時の文字コードはUTF-8です。そして次のように実行して下さい。
( Written by Tatsuo Ikura )
