Unicode文字列(ユニコード文字列)
Pythonでは通常の文字列とは別にユニコード文字列と呼ばれる型が存在します。通常の文字列は8ビット文字列と呼ばれるもので、1つの文字を複数のバイトに分解して格納します。日本語などの文字であっても複数のバイトを使うことで扱うことが出来ますが、Python側から見た場合はあくまでバイト単位での処理となりため色々と考慮しなければならない事があります。
それに対してUnicode文字列は文字をUnicodeとして扱います。日本語のような全角文字であってもアルファベットのようなASCII文字であっても1文字を1文字として扱います。通常の文字列がバイト単位なのに対してUnicode文字列では文字単位で処理が行えるわけです。その為、Pythonで日本語を取り扱う場合はUnicode文字列を使うようにします。
組み込み型 + 数値型 | + 整数 | + 長整数 | + 浮動小数点 | + 複素数 + シーケンス型 | + 文字列 | + ユニコード文字列 | + リスト | + タプル + マップ型 | + 辞書(ディクショナリ) + ファイルオブジェクト
Unicode文字列を作成する場合、プログラムで設定している文字コードによって異なります。まずは「UTF-8」を使用している場合は次のように作成します。
u"文字列" U'文字列' u"文字列" U'文字列'
「UTF-8」を使用している場合は、単に文字列の前に「u」又は「U」を付けるだけでUnicode文字列となります。
それに対して「Shift_JIS」又は「EUC-JP」を使用している場合は次のようにUnicode文字列を作成します。
unicode("文字列", "Shift_JIS")
unicode("文字列", "EUC-JP")
「unicode」関数はPythonで用意されている組み込み関数です。1番目の引数の対象の文字列、2番目の引数に文字コードを指定します。文字列を指定の文字コードを使ってデコードした結果得られるUnicode文字列を返します。
※文字コードの設定については「日本語と文字コード」を参照して下さい。
作成されたUnicode文字列は、通常の文字列とほぼ同じように取り扱うことが出来ます。例えば標準出力に出力する場合は「print」文を使って出力できます。
print u"日本語文字列"
またエスケープシーケンスも同じように記述できます。
print u"こんにちは¥nお元気ですか?"
またエスケープシーケンスを無効にするためのraw文字列も使用できます。この場合は「ur」のように先に「u」を指定して下さい。
print ur"こんにちはお元気ですか?"
では実際に試してみます。
#coding: UTF-8 print u"こんにちは¥nお元気ですか?" print u"Bananaの値段は1000円です"
上記を「test5-1.py」として保存します。保存する時の文字コードはUTF-8です。そして次のように実行して下さい。
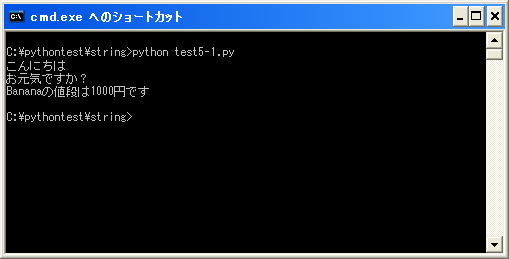
Unicode文字列では日本語だけではなく、英数字ももちろん扱うことが可能です。
( Written by Tatsuo Ikura )
